您好,欢迎光临kaiyun体育(中国)官方网站!
:
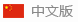


贝叶斯定理贝叶斯定理是关于事件A和事件B的条件概率。再行认识一下这几个符号:P(A|B):回应在事件B再次发生的情况下事件A再次发生的概率P(B|A):回应在事件A再次发生的情况下事件B再次发生的概率一般来说在未知P(A|B)的情况下,计算出来P(B|A)的值,此时P(A|B)可以称作先验概率,P(B|A)称作后验概率。这个时候贝叶斯定理就登场啦:通过这个定理我们就可以计算出来出有P(B|A)的值。
荐个栗子:一座别墅在过去的20年里一共再次发生过2次被盗,别墅的主人有一条狗,狗平均值每周晚上叫3次,在盗贼侵略时狗叫的概率被估算为0.9,在狗叫的时候再次发生侵略的概率是多少?我们假设A事件为狗在晚上叫,B为盗贼侵略,则以天为单位统计资料,P(A)=3/7,P(B)=2/(20*365)=2/7300,P(A|B)=0.9,按照公式很更容易得出结论结果:P(B|A)=0.9*(2/7300)/(3/7)=0.00058贝叶斯定理伸延只不过到这里只是贝叶斯定理的非常简单版,下面来想到它的一般版。一般事件B的再次发生好比有一个影响因素,比如事件B为早上否吃早餐,那么事件A1可以为几点睡觉,A2回应为早上否有课,A3天气否严寒,...An食堂早餐买到几点,这n个事件联合影响事件B否吃早饭的再次发生,此时各事件的概率就再次发生了变化:P(A)=P(A1,A2,A3,...An)P(A|B)=P(A1,A2,A3,...An|B)假设A1,A2,A3,...An都有两种结果,那么一共有2^n个结果,对应必须的样本数也是呈圆形指数减少,这似乎是相左实际的,这时,就明确提出了半朴素贝叶斯和朴素贝叶斯。这两个定理都有朴素二字,这二字什么意思呢?白话一点就是修改的意思,将A1,A2,A3,...An这n个事件的关联截断,假设它们是互相独立国家的,即P(A)=P(A1,A2,A3,...An)=P(A1)P(A2)P(A3)...P(An);P(A|B)=P(A1,A2,A3,...An|B)=P(A1|B)P(A2|B)P(A3|B)...P(An|B)这么一朴素,整个过程非常简单了好比一点点。
但是事件A1可以为几点睡觉和事件A2回应为早上否有课知道一点关联都没吗?认同是有关联的,将相关性很高的一些事件明确提出,P(A)=P(A1,A2,A3,...An)=P(A1)P(A2)P(A3)...P(An)P(A1A2);既不忽视事件的相关性,又享有朴素的特性,这就叫半朴素贝叶斯。半朴素贝叶斯朴素贝叶斯分类的月定义如下:1、另设为一个待分类项,而每个a为x的一个特征属性。
2、有类别子集3、计算出来4、如果则基于属性条件独立性假设,现在来计算出来P(y1|x),P(y2|x),...P(yn|x)。对于所有类别来说P(x)是完全相同的,因此只需计算出来分子部分。
在实际计算出来时,为了防止下溢(小数点位数过低),一般不会对等式两边同时展开Ln变形,将*变成+;这里ln为一个增函数,因此可以确保不转变P(yn|x)的大小排序。另一个必须留意的点是:样本数是受限的,不有可能还包括所有的情形,这时不会经常出现P(xn|yi)=0,但是这种情况不经常出现是不等价于不再次发生的,这是中用拉普拉斯修正展开光滑:P(xn|yi)=(N(结果yi再次发生的前提下xn再次发生的次数)+1)/(结果yi再次发生的次数+属性xn所有有可能的给定)数据预处理右图是这次要中用的原始数据,一行代表一则广告。
ham代表简单的广告,spam代表垃圾短信。预处理一共有三部:第一步:将数据读取进去。
defread_txt():file='C:/Users/伊雅/Desktop/bayes.txt'withopen(file,encoding='utf-8')asf:con=f.readlines()returncon第二步:广告存到dataset中,分类结果存储到txt_class中,获得一个词汇表将dataset中的广告用作split为一个一个的单词,并将长度大于1的单词去除(a)defcreate_word_list(con):reg=re.compile(r'W*')dataset=[]wordlist=set([])txt_class=[]foriincon[1:]:dataset.append(re.split(reg,i)[1:])wordlist=wordlist|set(re.split(reg,i)[1:])ifre.split(reg,i)[0]=='ham':#简单的邮件txt_class.append(1)else:#垃圾邮件txt_class.append(0)wordlist=[iforiinwordlistiflen(i)>2]returndataset,wordlist,txt_class第三步:对每一个广告做到循环,通过函数words_vec输出参数为每则广告的单词以及词汇表wordlists,回到一个文档向量,向量的每一个元素为0或1,分别回应词汇表中的单词在广告次中否经常出现,如果经常出现该单词的index则改版为1,否则则为0。defwords_vec(txt,wordlist):returnvec=[0]*len(wordlist)forwordintxt:ifwordinwordlist:returnvec[list(wordlist).index(word)]=1returnreturnvec经过这三步把单词文本转化成为了数学向量,大大简化了计算出来。
本文来源:kaiyun体育(中国)官方网站-www.5179e.com


+86 0000 88888

19259817173
Copyright © 2006-2024 www.5179e.com. kaiyun体育(中国)官方网站科技 版权所有 :贵州省毕节市沁水县瑞标大楼53号 :ICP备71298857号-1



